Terminology
Part 4 Chapter 5
Health
The English word Health is used extensively in IT industry for decades, but nobody takes the time to define it subjectively.
You certainly want your environment to be healthy. The desire to achieve that nirvana state results in a definition that is too broad as you try to cover everything. When the health metric covers too many things, you can end up with low score and yet everything is running well!
Health is hard to define, as it depends on the context and object. The English word health itself is subject to interpretation. How healthy are you? For example, I exercise regularly and can perform many rounds of pull ups, push up, deadlift and squats. I’m physically healthy. Biologically though, I’ve been suffering from irritable bowel syndrome and sleep disorder. As for mental health, my wife thinks I have a big problem 😊
Let’s try another real-life context. How healthy is your country? Let’s take the world superpowers (USA and China). Both are well accepted as superpowers, in both economy and military. But how healthy are they?
The answer depends on which aspect and which provinces you’re talking about. It needs to have more context. That’s why you do not have a single score for health.
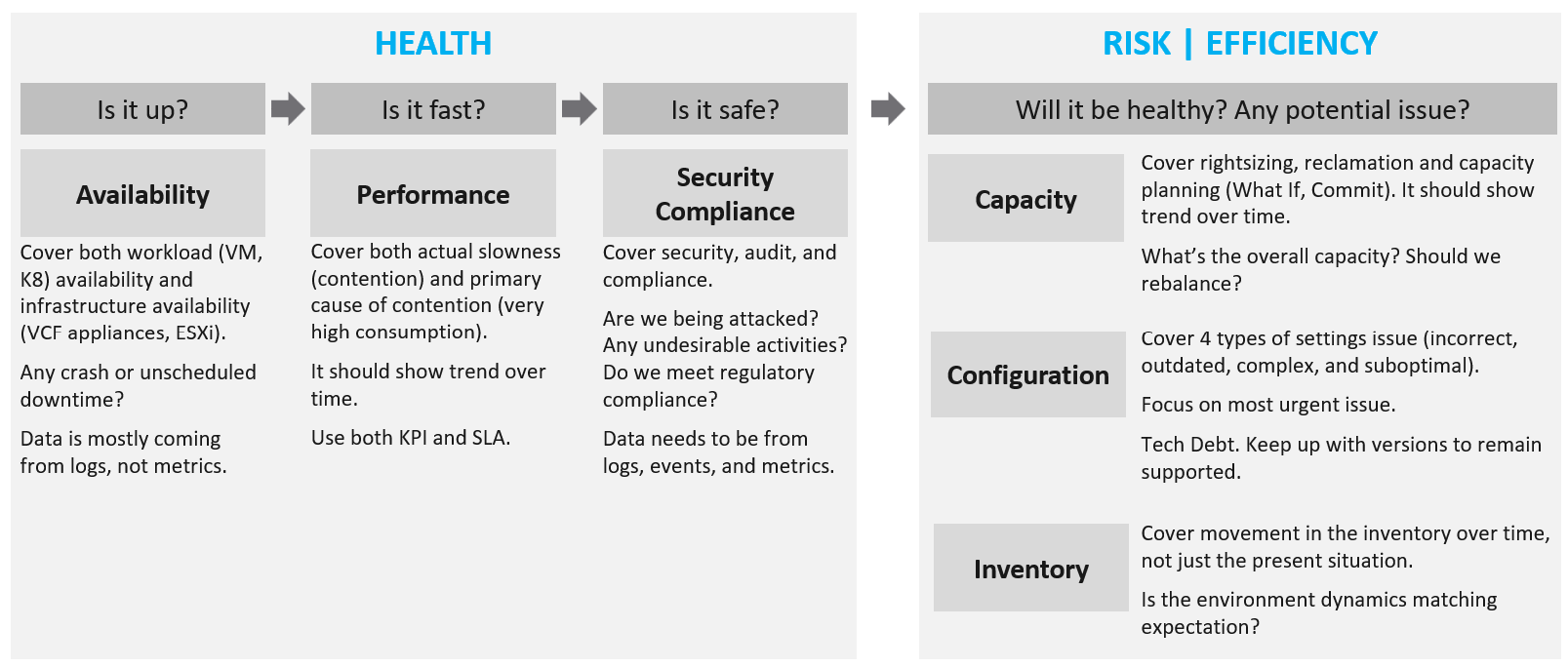
If you insist on defining “health”, then my recommendation is map it to the pillars of operations. When you do that, you vrealize that there are 3 sides of health, not 1. Since there are 3, you need to have 3 different metrics.
| Present Health | Your health in the present time, especially right now. It covers real problem that has happened and/or is still ongoing. The present health only includes reality. It does not include possibility. That’s covered under Risk. Just because you have security risks does not mean you’re being hacked. | |
|---|---|---|
There are 3 problems that impact the present health:
Availability and Performance are related, which means they are not the same thing. Your environment can be 100% up but slow. Security has 2 parts: present and future. The present health only covers actual security issues. For example, your environment is running fine, but you notice unauthorized access & suspicious commands being issued in your ESXi consoles. | ||
| Future Health | It covers potential problems. There is no problem at this moment, but if you do not act on it, you increase the risk of it becoming a problem. Using a day-to-day life analogy, you are healthy now but have a risk of heart problems if you do not stop smoking, are lacking sleep, consuming unhealthy diet, and are overweight. | |
There are 4 problems that create risk in operations:
| ||
In all the above problems, the present health is not impacted as there is neither slowness, downtime, nor security breach. What you have is a risk, as your applications and operations continue as if nothing happens. Your data has not been stolen. Your customers do not notice, and your business is not affected. Let’s take an example. You do not configure HA in a vSphere cluster. If all ESXi hosts are running, your availability is 100%. Your performance is also not impacted. However, you have an availability risk. | ||
| Better Health | This is about effectiveness and efficiency. Effectiveness is about doing the right things. Efficiency is about doing things right. You can operate the wrong architecture correctly. Efficiency is about optimization. There is no health problem at present, nor is there a health risk for future problems. You want to increase efficiency as it lowers cost, reduces complexity, reduce capacity footprint and improve application performance. | |
There are multiple ways to increase efficiency, hence the definition varies among objects.
Green Operations fits efficiency as sustainable operations call for lean operations. | ||
Observability
Observability needs to be built-in, not bolted-on, in your system architecture. That means ensuring it can be monitored clearly, down to the smallest component. Do not deploy system into production that can’t be properly monitored. Unfortunately, this is typically the last thing in our IT industry, especially with tight deadlines, limited skills and low budgets. Many applications, software, and hardware do not systematically leave trails for post-mortem analysis.
To “solve” the above problem, our IT industry came up with new buzzwords and make them larger than life. You hear jargons such as observability, unknown unknown, golden signal, SLO, SLI, and reliability. Observability is pitched as more than monitoring + troubleshooting, although it’s just a nature of a system.
It is certainly important to elevate the proactive work to detect unknown problems that you are not even aware of. I love slicing and dicing millions of data points (metrics, logs, events, traces, NetFlow) and discover new insights. It also helps me understanding the behaviour of low-level metrics better. Many times, they are not what the manual says as documentation on metrics is often not deep. I’ve discovered a few dozen bugs in metrics in the last 1+ decade.
CIOs should not only encourage, but also require the subject matter experts to allocate time to this proactive exploration. It should be part of a regular cadence to share work and findings. It’s both a good exercise to keep the knowledge deep, plus you never know what you will discover!
Having said that, do we need a new term? I don’t think so since it has caused confusion. Lots of software can do this, along with many other things. It’s all part of monitoring and troubleshooting. There is no need to invent a new category of software. This is the classic “old wine in a new bottle” trick.
If we really want a new term, the word debuggability carries more value as just because a system is observable does not mean you can do something to fix it, let alone intervening to debug it. It is painful watching your system deteriorate with nothing you can do about it. In modern days, debugging is no longer limited to slow and manual process of stepping through code. It can involve in-line analytics as the codes processing. This certainly requires the system to be built with debuggability in mind.
It is as if observability and monitoring are not confusing, there are other English words used to monitor a system:
-
Finding
-
Insight
-
Issue
-
Alert
-
Symptom
-
Notification
The following diagram shows how they are related.
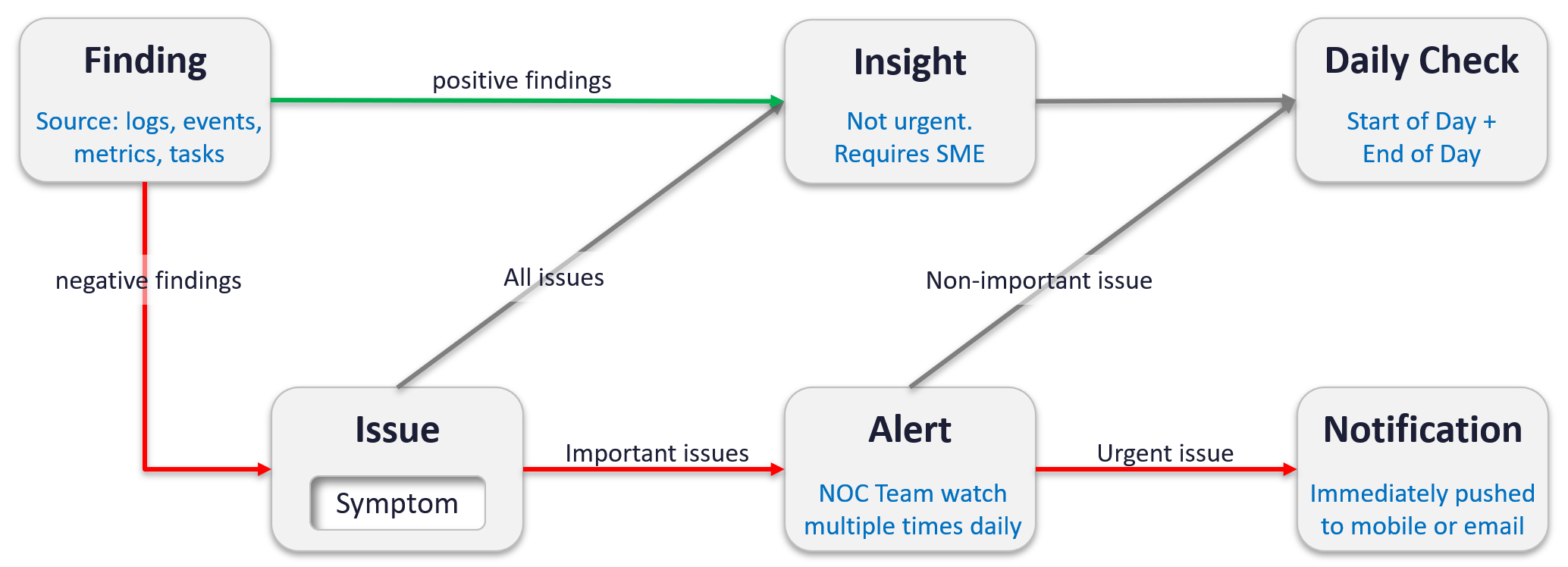
| Finding | Finding is what is found. It is the result of diagnostic or analysis. It can be bad things or good things. Bad = Issue. Since the sources of finding (logs, events, metrics and tasks) focus on negative, a no entry typically means it’s a good day. For example, you find no login to a confidential cluster. Findings are input to Insight. Generally speaking, it takes someone who is familiar with the environment to derive an insight from findings. |
|---|---|
| Insight | A useful observation with real business benefit. This typically requires someone with both technology expertise and familiarity of the environment. Findings are input to Insight. An expert can derive an insight from findings. |
| Issue | An issue is identified by its 1 or more Symptom. No symptom simply means no issue, you are healthy. |
Type of Issues:
| |
| Alert | It’s an urgent Issue with Symptom crossing threshold. An issue that is urgent (may not be important) needs to reach Admin fast. Admin wants to be notified. An issue that is not urgent (but important) can be analysed after Admin are done with time-sensitive issue |
| Notification | A mechanism for VCF Operations to inform users of insights or alerts that need their attention. This takes different format:
|