Your Private Cloud
Part 1 Chapter 1
This first chapter provides a tour of IaaS operations management, starting with why reactive and hectic operations is common, and the paradigm shift required to proactive & predictive operations.
Overview
What you architect is SDDC. But what you handover as a business result to your CIO is IaaS. What you bought from your vendor is SDDC, but what you sell to your customers is IaaS.
The transformation from SDDC to IaaS requires Operations Transformation. We transform from complaint-based to SLA-based, which requires fundamental process changes from alert-driven to insight-driven.
SDDC is a system, IaaS is a service. A system cares about its architecture, while a service cares about its service level.
Whether the Application Team or VM Owner pays for the service with a chargeback model or not, it is a service. VM Owners no longer own, hence care, about the underlying architecture.
They are 2 sides of the same coin. We can assess if the architecture is good or not, based on the actual result in production. Does it result in firefighting and blamestorming? Or do you have peaceful operations where alerts are meaningful and actionable?
Many operations rely on alerts as the starting point. Actions are taken based on alerts, resulting in reactive day-to-day operations.
IT Operations covers a wide area of systems. It’s common to see more than 1K alert definitions across all systems under monitoring. As the team wants to be alerted early, a conservative threshold is set up. This results in alert storms.
Since automation is perceived as the holy grail of solutions, alerts are typically set to auto close if the symptom disappears. The creates a bigger problem, common in large enterprises with a large IT team. That problem is “lazy operations”, where no alert is associated with no problem.
Complaint-based Operations
How do you know that the Infrastructure as a Service (IaaS) Platform (be it on-prem private cloud or externally in the cloud) is serving its workload well? If you depend on complaints, then you run “complaint-based” operations.
Changing from reactive to proactive is unfortunately a complex undertaking, especially in large organizations where there are many roles and personas. It requires operations transformation and a paradigm shift. It is not easy to get customers to agree on a Service Level Agreement (SLA) when you’ve promised them “good” for years already. This book aims to provide practical guidance, something you can implement with the current version of Aria products.
The Litmus Test
The following questions below helps you assess the maturity of your IaaS business.
Is your IaaS cheaper than public cloud?
The commoditization of infrastructure means your IaaS is being compared with similar platforms such as VMware Cloud on AWS and Amazon Web Services.
If not, your CIO may question your business value. The primary reason for having an in-house architect is so you can bring better price/performance, after taking into account your salary.
Do your customers blame your IaaS?
If the answer is yes, take a moment to ponder why. There is a high chance you are relying on complaints in your operations, so you actually encourage them. No complaint, no problem. That’s why it’s aptly named Complaint-based Operations.
The reason why you rely on complaints is the operations team have no other means by which to measure success. You have not defined the performance of your IaaS. That’s one of the goals of this book.
A sign of matured operations is that you have complete, correct, and accurate SLAs (Service-level agreements). Complete means you have Performance SLAs and Compliance SLAs, not just Availability SLAs. Correct means the SLA is measured on each paying VM, and not at the infrastructure level. It also means you use the right metrics. Accurate means the measurement has to be measured every 5 minutes, as any longer intervals than this can miss the problem.
Does troubleshooting mean all hands-on deck?
Do you have a process that is followed by all teams (network, storage, server, OS, application)? Does that process end with Root Cause Analyzis (RCA)?
As part of RCA, do you set up alerts so the same issue can be detected faster if it happens again? Without an alert configured, the RCA should not be closed. The alert is necessary as it will trigger the next RCA process.
Does Help Desk provide a good first level defence?
If Help Desk simply passes issues through to the next level, you need to look at why.
Help Desk is your first line of defence. They are not as technical as you are. Equip them with Standard Operating Procedures and simple dashboards so that they can handle VM Owner complaints by discovering:
-
Is the problem caused by IaaS not serving the VM well?
-
If yes, which part of the infrastructure: CPU, RAM, Disk, Network?
-
If not, how to prove it convincingly?
Do you struggle with many over-provisioned VMs?
This is an indicator that you are operating as a System Builder as opposed to a Service Provider. As a System Builder, you are meddling with each System (read: Application). You size them and argue with the application teams, who are actually your customers. You are busy as there are many applications, and you are outnumbered.
If you are operating as an internal Cloud Service Provider, you should not be “in the way” of the business. You use an effective pricing model to drive the right behaviour. Does a public cloud provider block application teams when they buy 40 CPU AWS EC2 VMs when they only need 2 CPU? They don’t, hence neither should you.
Can you justify new infrastructure when utilization is not high?
This is not referring to additional money that comes with new projects. This is referring to existing workloads on existing clusters/storage.
Capacity is measured on utilization and performance. A cluster is at full capacity if it can’t serve its VMs well. Since it takes time to buy hardware, you must have an early warning system to detect this performance degradation.
Common Mistakes
“If you don’t have a problem, I don’t have a solution” summarizes how I engage customers. After >1.5 decades of engagements with hundreds of VMware customers and outsourced partners, here are typical mistakes I’ve observed:
-
Using automation as the primary solution for transformation.
-
Private Cloud is seen as automation project as opposed to operation. Private Cloud is not virtualization with automation and self-service. It is the required technical foundation to transform the business of enterprise IT from system builder to service provider. The automation, workflow and self-service portal are merely supporting features. The primary components of Private Cloud are SLAs and Class of Service, hence it’s operations-centric, not automation-centric.
-
VMware Cloud Foundation is architected with server-consolidation mindset. That means the system has no awareness of IaaS and SLAs. Different classes of service are mixed in the same cluster or datastore.
-
There is class of service, but the system does not clearly state it. The naming standard does not include class of service.
-
Performance is never defined properly. The infrastructure is designed for performance, but the benchmark does not align with what actually being sold. There is no Performance SLA, and often there are no Key Performance Indicators (KPI)1.
-
The infrastructure has no awareness of business units, applications, or application-tiers. The business is not reflected in the infrastructure.
Maturity Model
It’s a good practice to assess the level of operational maturity, as it allows you to summarize where you are. There are different variants of this models, so don’t be hesitant to tailor to your goals. I’ve included a short assessment within Part 4 Chapter 1 to get you going.
When scoring yourself, assign score on the following area:
-
Policy: Is your policy outdated? Best Practice typically means proven or common practice.
-
People: How skilful is the team vs the need? This includes the way the team is organised.
-
Process: How effective are the key processes (e.g. planning process, troubleshooting process)?
-
Pillar: How mature is each pillar of operations? For example, if your capacity management is mature, you are balancing cost and capacity very well. If your performance management is mature, you’re not reactive to endless complaints because you have SLA formally agreed.
-
Platform: This covers both the technology supporting the business workload, and the IT tools used by the operations team to support the former. For example, if you do not have clear visibility, you’re flying blind.
Multi-Cloud Management
A single private cloud - something you have complete control of - is hard enough to operate, let alone operating multiple incompatible infrastructures. Multi-cloud operations, where you are responsible for something that you do not have complete controls take the operations challenge to the next level. Don’t be disheartened if your organisation is struggling with running multi-cloud operations.
The complexity is due to the immaturity of the architecture. There are simply too many components involved, as shown in the landscape diagram by Cloud Native Computing Foundation. The individual products that make up the architecture is not important, hence I intentionally make the diagram small.
Eventually though…, the architecture will slowly mature and turn into a commodity. CIOs will begin to focus on the operations, as the business will demand proper governance with SLAs.
Regardless of the underlying system architecture, CIOs are still required to manage cost, capacity, compliance, performance, and availability. The Pillars of Operations do not change just because you change the plumbing.
The Business of IaaS
There are 3 variants of an IaaS business. They differ in terms of what you actually sell, how you do pricing, and what SLA you put on the table.
| Item | Pricing | Availability SLA | Performance SLA |
|---|---|---|---|
| VM | Price depends on VM size. A larger VM has a higher price. Price depends on quality. A better tier has a higher price. Example of an item purchased: 1 VM, 4 vCPU, 16 RAM, 200 GB disk, in Gold Tier. | Per VM. Depends on the tier. | Per VM. Depends on the tier. |
| Resource Pool | Sold per GHz, GB RAM, TB Disk. Example of item purchased: 100 GHz CPU, 1 TB RAM, 80 TB Disk. It can come with a 100% reservation; hence it’s guaranteed. Alternatively, it may have partial reservation. It typically comes with best effort burst, in the form of expandable resource pool. On the other hand, it may come with a limit but it’s always higher than what you paid for. For example, you pay for 1 TB of RAM. You can have 0.5 TB guaranteed and a 2 TB limit. | Per VM. Limited tiering capabilities. | N/A. While Resource is reserved, customer is allowed to overcommit within their own limit. It’s not something the IaaS service definition imposes. |
| Hardware | Price per ESXi host. Customers decide how many VMs they want to place. HA is provided by vendor. Example of items purchased: 8 ESXi Hosts. Example provider: Azure VMware Solution (AVS). | On the Host or Cluster, not VM. | N/A Customer can squeeze as many VMs. |
Class of service is harder to implement in resource pools as there are more moving parts. You can have cascading resource pools.
VM as a Service
The most popular variant of IaaS is VM as a Service. It is typical example of “buy wholesale sell retail” business. You buy in bulk (hardware, software) and commit DC space for years, then sell in small chunks (VM, K8 Pod). You make profit as your buy price is several magnitudes lower than your sell price, on a per unit basis. You probably pay 5x less per GHz than you sell.
| Purpose | Serve the workload. They take the shape of VMs. The VMs in turn can be K8 nodes or classic applications. The workload must be grouped by tenant and business applications. |
|---|---|
| KPI | The key metrics used to measure the performance of the infrastructure. Is it serving the VMs according to its SLA? |
| Cost | The total cost should be cheaper than public cloud. Typically, customer aims at >2x cheaper, not just marginally cheaper. |
| Pillars | The key pillars that transform the SDDC into IaaS. IaaS has multiple class of services. Each has their own Availability SLA, Performance SLA, Security SLA, and Service SLA. |
| Proof | The metrics demonstrating that the architecture works as intended. Operations become proactive. It’s based on insight, not alert. |
The business goal is to ensure the application and VMs are running well yet cost effective. In this way, you keep the customers happy.
The cost part is easy to quantify. You know what you actually spend on hardware, software, services and salary. The “well” in running well is the hard part as there is a big unknown. This is also the source of argument between application teams and infrastructure teams.
Say you are architecting for 10K VMs in 2 data centers. You envisage 2K VMs in the first month, 5K VMs in the first half year, and eventually to 10K within the first year. Do you know the basic info about each of these 10K VMs, so that you can architect an infrastructure to serve them well?
-
How big are they? What are their vCPU, RAM, and Disk configuration?
-
How intense are they? CPU utilization, RAM utilization, disk IOPS, network throughput?
-
What are their workload patterns? Daily, weekly, monthly, no pattern, etc?
The answer is obviously no. Even application teams do not know as some of the applications may not be developed yet. Their vendors may not know either as the actual usage is not yet known.
Promising that the SDDC will serve all 10K VMs well is akin to promising the highway you architect will serve all the cars, buses and motorcycles well, when we can’t predict how many they are and how often they will use it. We will cover this more in the Performance chapter.
So how can we promise that your IaaS will serve your customers well?
We can by using price/performance. The principle you share with your customers is the common sense principle used in all service industries:
-
You want it cheap; it won't be fast.
-
You want it fast; it won't be cheap.
This is where the Class of Service and the associated SLAs come in. The highest class of service provides the best uptime and performance but comes at a price. All these attributes are well defined in the SLA, leaving no room for ambiguity. The contract is not subject to interpretation. You define all the key metrics up front, assuring your customers that you are confident of delivering as promised.
You then architect your IaaS to deliver the above class of services. The class of service becomes your business offering. With that, you are ready to begin with the end in mind.
Capabilities
The platform should provide a complete self-service portal for all types of users. The features should cover all stages in the life cycle, starting from provisioning. Provisioning should have an SLA and be supported with workflows and electronic approval.
Key Metrics
You measure across the pillars of operations management. Each pillar is measured, hence managed, by a purpose-built metrics. This enables you to manage at scale.
| Pillars | Metrics | |
|---|---|---|
| Availability | Operational Availability (%) | Relative Availability, against your availability architecture and green zone. |
| Actual Availability (%) | Absolute availability, reporting the fact as it is. This metric typically has lower value than Operational Availability (%). | |
| Performance | KPI (%) | Absolute performance, reporting the fact as it is. |
| SLI (%) and SLA (%) | Relative performance, against your promised SLA. SLI = SLA Leading Indicator | |
| Capacity | Capacity Remaining (%) | Relative to usable capacity, not total capacity. |
| Time Remaining (days) | The number of days until Capacity Remaining (%) hits 0. | |
| Compliance | Benchmark X (%) Compliant | Compliance against specific industry or internal benchmark, such as PCI-DSS. 1 metric per benchmark. |
The Restaurant Analogy
Sunny Dua2 and I use the restaurant analogy when explaining the need of SLA. The analogy has resonated well with many customers. Humans can always relate to food!
Essentially, a restaurant has 2 areas, often with a clear demarcation line:
-
The Dining Area.
-
The Kitchen.
Think of your IaaS business like a restaurant business. It has a dining area, where your customers live, and a kitchen, where you prepare the food. Guess which one is more important to the owner?
You are right. The dining area.
If everything runs smoothly in the dining area, customers are being served on time and on quality, and they are paying you well; it is a good day for the business. Whether you are running around in the hot kitchen is a separate, internal matter. The customers do not need to know about it.
We use the analogy to drive the message that you need to focus on the customers first, and your SDDC second. If you take care of your customers well, and they are happy with your service, the problem you have in your IaaS is a secondary and internal matter.
-
The “dining area” is the Consumer layer. Look at the diagram below. It is where your customers’ VMs live. In the public cloud such as AWS, that’s all you can see.
-
The “kitchen” is the Provider Layer. This is your infrastructure layer, where VMware and the hardware reside.
Public cloud is part of the kitchen. Just because you no longer own the infrastructure does not mean you don’t take management responsibility. The structure of enterprise IT means the infrastructure team ends up being held accountable.

There is clearly a line of demarcation between the two layers. Your customers should not care about the details of your SDDC or EUC. The VM Owner does not care if you are firefighting in the data center. Because they do not care, whether you are using an older VMware Cloud Foundation or the latest, this is not something you want them to dictate to you. The same goes with your choice of hardware brand and specification.
Conduct regular sessions with the application teams on the following topics:
-
How to run best on VMware, with optimal performance, highest availability, most secured while keeping cost minimal.
-
How to monitor the performance, availability, and security when you’re running on VMware. How to know you’re being served well by the IaaS platform according to the promised.
-
Windows and Linux performance best practices.
-
Why rightsized is better than oversized for VM.
Understand their expectation of the infrastructure. In large environments, different VM Owners can have different expectations and levels of knowledge.
The application teams become consumers of a shared service—the cloud platform. Depending on the SLA, the application teams can be served as if they have dedicated access to the infrastructure, or they can take a performance hit in exchange for a lower price. For SLAs where performance is guaranteed, a VM running in the cluster should not be impacted by any other VMs. The performance must be as good as if it is the only VM running on the ESXi host.
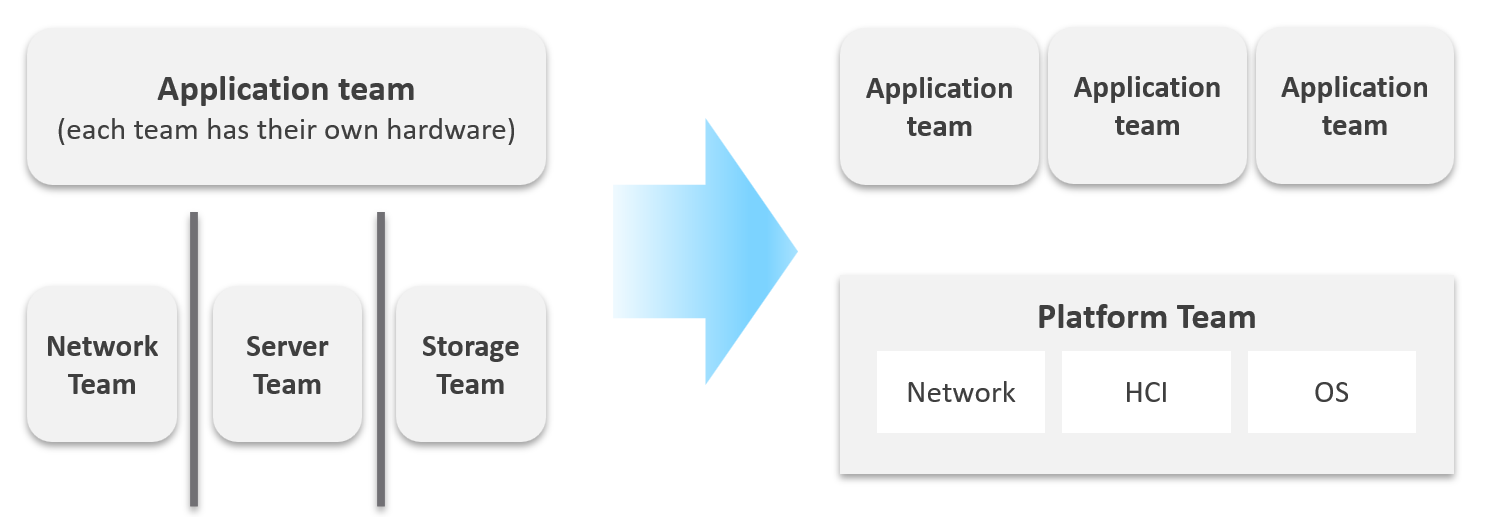
Let’s zoom into the kitchen area, as that’s also undergoing a transformation. The Server team or Windows team or Linux team typically took the ownership of the shared platform and evolved to become the platform team. With the evolution of Hyper Converged Infrastructure, storage is being absorbed into the platform. The boundary with the Network team is also becoming blurry with network virtualization. Many network services such as Firewalls and Load Balancers are virtualized. Recently, with the arrival of the Kubernetes, the platform team began owning containers and K8s, plus there are new teams (DevOps and/or SRE) that sit in between Platform team and Application team.